关于TSNE实现数据降维可视化的理解
TSNE:最直观的理解就是计算高维空间的特征相似度概率(高斯分布)然后投影到低维空间(t分布),并保证这种相似度得以保留(KL散度),其实也是Embedding的一种
下面是可视化的代码:
1 | |
降维后的节点坐标用二维数组z表示,颜色用c表示(其实在节点分类问题里面对应的是节点标签)
实际调用可视化函数的代码块为:
1 | |
这里解释一下传递的参数:
out:模型输出的结果,这里其实输出的是一个嵌入向量
data.y:数据集的真实标签
所以相当于是经过不同的模型会对特征做不同的处理
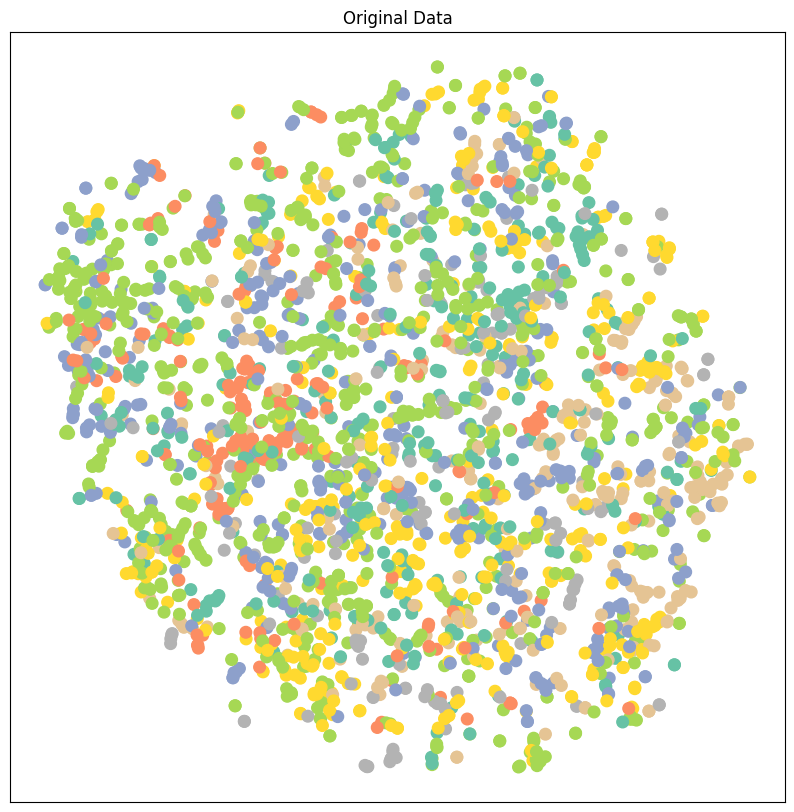
比如说经过一个没有训练的GCN,那特征相当于是随机化处理了一下,没有什么明显的相似度,所以降维以后数据点还是乱的
如果经过一个训练好的GCN,那么特征就会结合拓扑结构重新实现嵌入,相似度明显提升,这时候再去做降维,那么就能看到节点位置发生了改变,会形成明显的簇
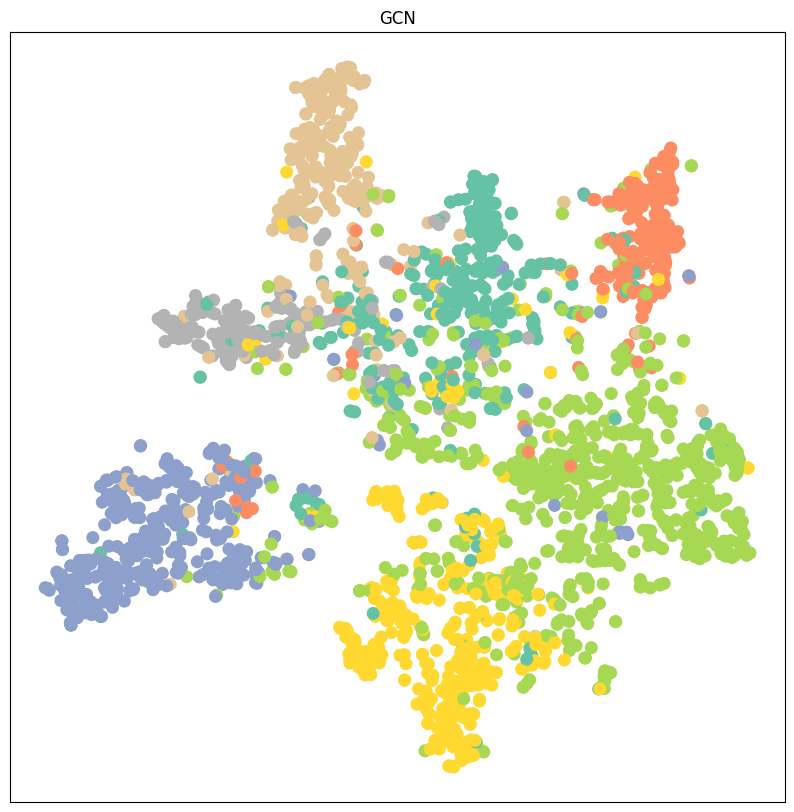
总结:TSNE图中,颜色代表真实的节点标签,节点的位置关系表示了特征的相似程度,所以相同颜色的节点越靠近、不同颜色的节点界限越清晰,说明特征嵌入越有效、分类结果会更准确!
关于TSNE实现数据降维可视化的理解
http://example.com/2025/02/27/关于TSNE实现数据降维可视化的理解/